Just wanted to throw an article together with some tips on how to maximize Veeam data moving performance when a high speed, higher latency, potentially lossy, link is involved. In my case, I had a point to point Cogent 10gig circuit between two data centers, with about 55ms RTT latency. Being Cogent, it will also lose 0.5-1% of packets in bursts occurring at 5-10 second intervals, it will lose packets at session startup, and it will not perform well with single TCP streams.
My Veeam environment includes HPE StoreOnce appliances at multiple data centers, and groups of both Windows Server 2016 and Ubuntu proxies. Some backups run across the WAN links so they can write directly to the disaster recovery location rather than having the wasted capacity, and delay, of writing locally and then replicating. Keep in mind that for some dumb reason HPE hasn’t made their acceleration client, Catalyst, available on linux, so even if you have linux-based Veeam proxies, one or more of your Windows-based systems is still going to be involved in the gateway role, moving data the linux proxy reads to the StoreOnce appliance.
So, first optimization. Get your StoreOnce code up to a version where Catalyst stores gain a “fixed block chunking” setting specific to Veeam usage. It makes a noticeable improvement in Catalyst performance. It unfortunately does require Veeam 12, and a new store, which you’d have to then move your jobs to or new writes won’t dedupe against them, meaning you’re going to double your storage utilization until they age out. Moving them can take a nightmarishly long time if you have a significant amount of data. It is what it is though, the backups need to be in the new format.

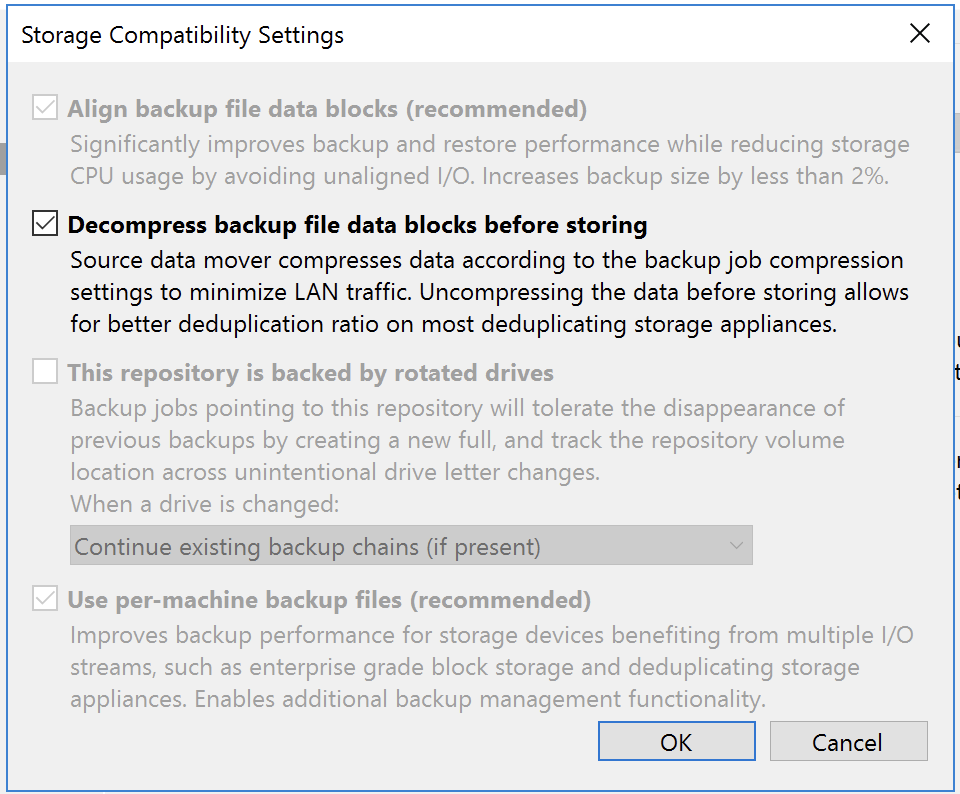
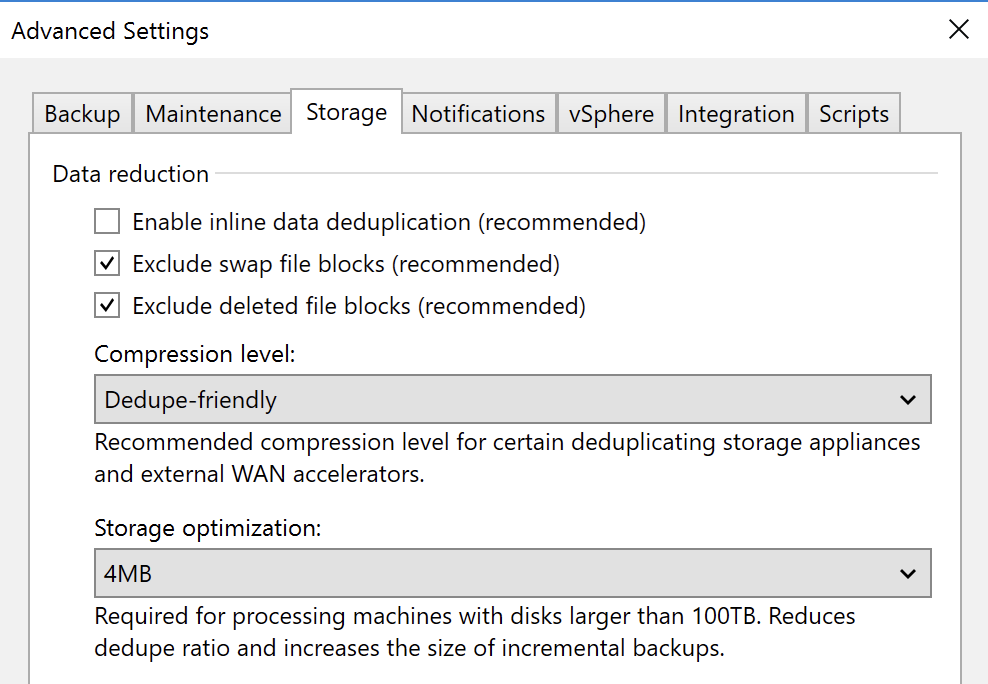
Now, set your Veeam jobs to use the new Catalyst store with all the optimal settings. At the appliance level, see the following, which are all forced except for the necessary decompress before storing:
At the job level, these include exclusion of swap and deleted file blocks, compression set to dedupe friendly, and ensure your block size is 4MB. You could potentially go with higher levels of compression if there is a slower speed link between your gateway and the StoreOnce, as then you can burn CPU time in favor of getting more data across a saturated link. In general, Catalyst involves overhead, and on a WAN link, the added latency and Catalyst overhead can make your backup perform horribly if you use a small block size, as that’s potentially 4x to 16x more Catalyst interactions per chunk than if you’re at the maximum 4MB size.
In some recent efforts to get Vmware vMotion working faster across these types of high latency and lossy WAN links, I learned of the BBR TCP congestion control algorithm. BBR performs dramatically better than anything else on high speed circuits that behave like this; i.e. not running at capacity, but exhibiting characteristics that other congestion control algorithms interpret as being at capacity.
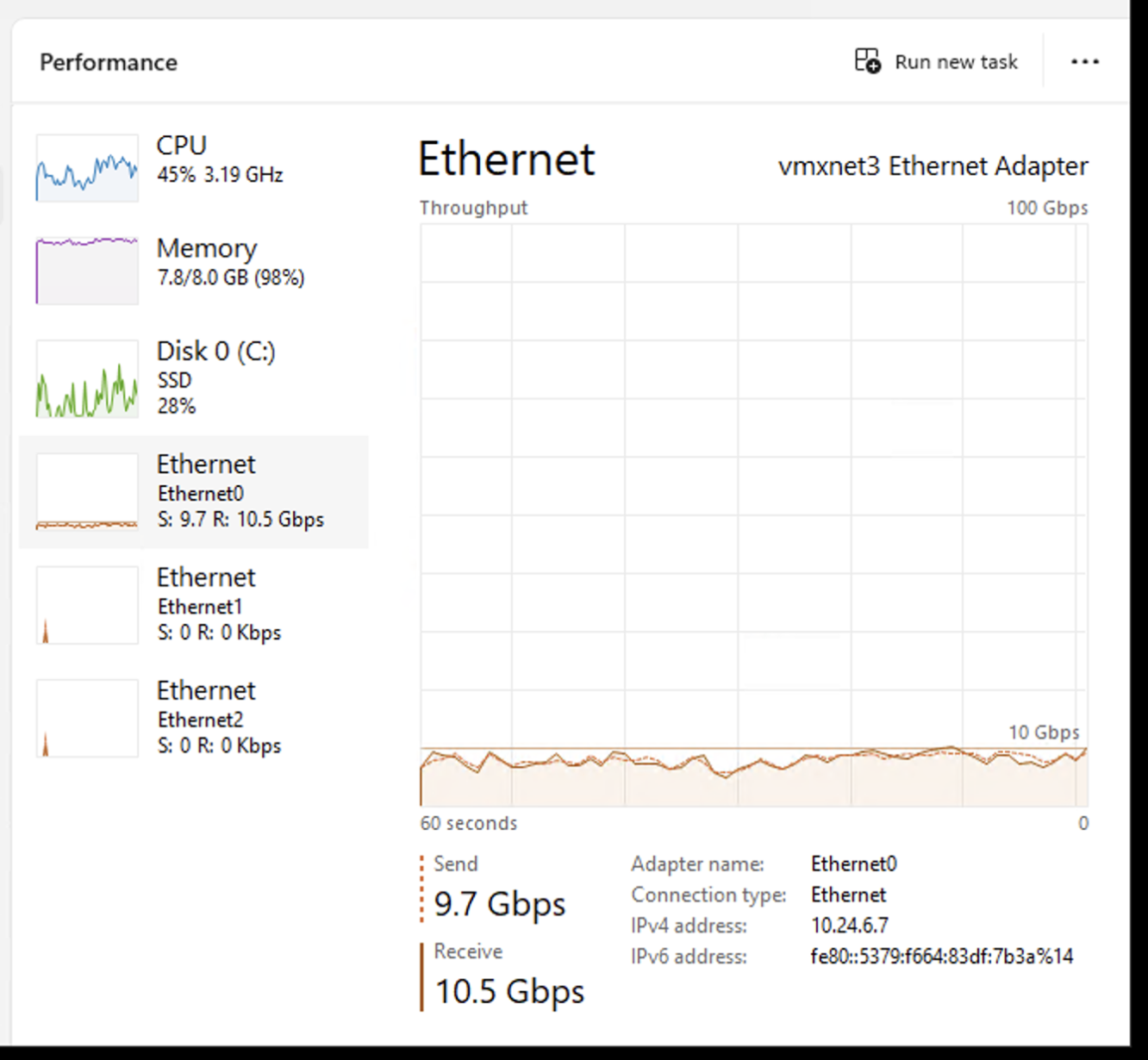
Knowing Windows 11 gained support for BBR, I thought perhaps I should try that for a Veeam proxy instead of Windows Server 2016 (and it’s cheaper). I threw a Windows 11 system in and configured it as both a Veeam proxy and the gateway to use for one of my remote StoreOnce appliances. It did indeed seem to have a positive effect, with throughput getting into the many-gigabit range. Here’s how you set that on Windows 11:
netsh int tcp set supplemental Template=Internet CongestionProvider=bbr2
netsh int tcp set supplemental Template=Datacenter CongestionProvider=bbr2
netsh int tcp set supplemental Template=Compat CongestionProvider=bbr2
netsh int tcp set supplemental Template=DatacenterCustom CongestionProvider=bbr2
netsh int tcp set supplemental Template=InternetCustom CongestionProvider=bbr2
Get-NetTCPSetting | Select SettingName, CongestionProviderCode language: JavaScript (javascript)After working with Veeam support to see if I could speed this environment up even more, I learned of both a useful setting, and recommended architecture change.
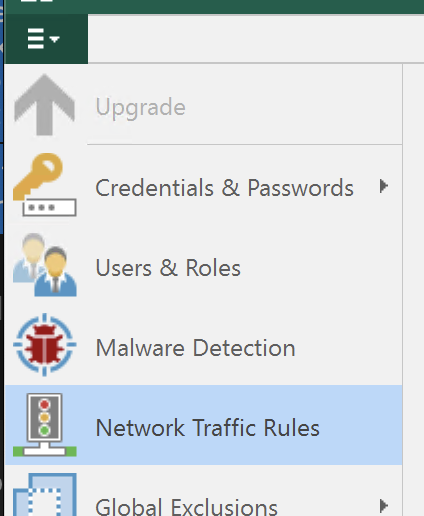
- The setting change is of particular importance if using a Cogent point to point link, as they become very lossy under single TCP session streams that push beyond a gigabit. The setting can be found in the “hamburger” three-bar menu in the upper left of the Veeam B&R console, then Network Traffic Rules, and it’s labeled “Use multiple upload streams per job”. This will let you both enable, and tune the number of streams to use, which you can use to adjust how Veeam behaves. It may allow you to match your WAN config, or could also be useful if you have traffic traversing an LACP or other type of link bundling that can hash by TCP port vs just source/destination.
- The architecture change was their recommendation to deploy a “gateway” server near the target StoreOnce. This allows a Veeam proxy to send data to the Veeam gateway using Veeam protocols, at a much higher speed than what Catalyst/StoreOnce can do across a WAN, and then of course subject to any optimizations you may do in your proxy/gateway setup, such as in my case using Windows 11 with BBR.
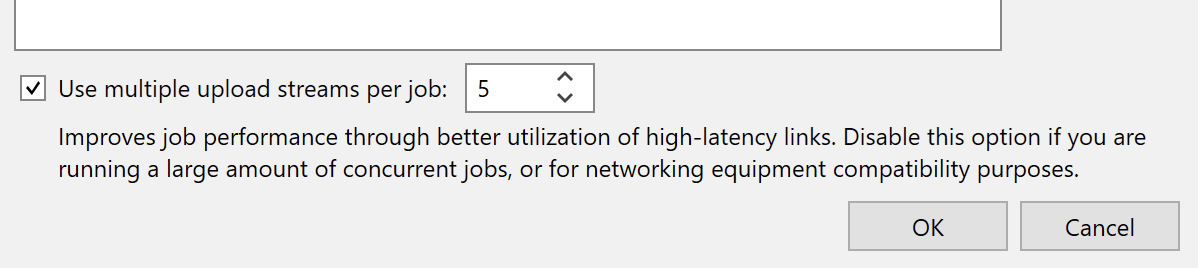
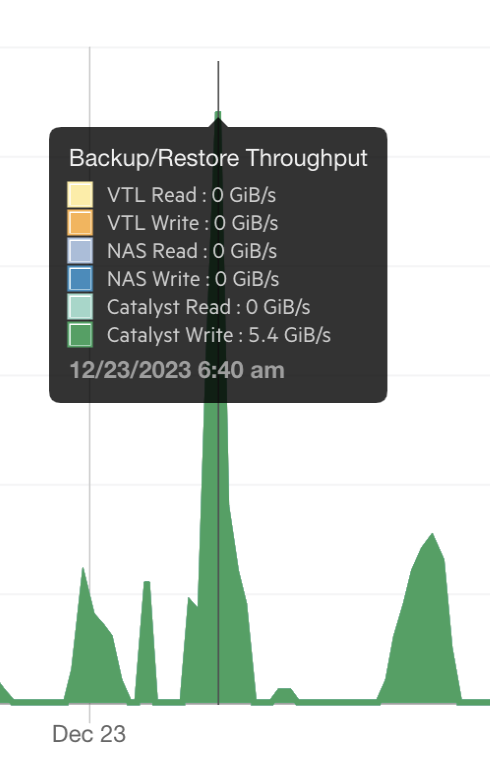
With all of the above in place, I achieved both wire speed 10gig throughput across this lossy link, AND multiples of that in actual data throughput with the Catalyst data reduction allowing blocks that already existed to not be sent. I’d often see effective 1.6-2 GB/sec Catalyst throughput, or even peaks as high as 5+ GB/sec.