I was trying to upgrade a VMware vSphere ESXi 5.1 server to version 5.5 this evening and I wanted to do it via the ‘recommended’ VMware Update Manager method. Last time I did it the manual way which is a real pain in the ass when you have a whole bunch of hosts to upgrade. In any case, I did the typical steps of going to Update Manager, ESXi Images tab and loaded in the current ISO for ESXi; a file named:
VMware-VMvisor-Installer-5.5.0-1331820.x86_64.iso
I created an upgrade baseline with the new image and assigned it to a specific host. I went to that host, Update Manager tab, did a “Scan…” to check it and it showed my upgrade as having an alert:
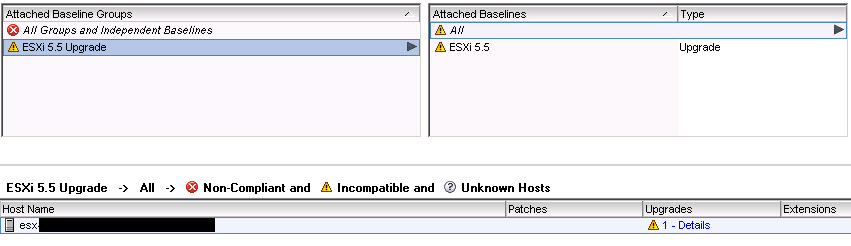
If I clicked on the little alert icon it showed me the following:
Cannot create a ramdisk of size 331MB to store the upgrade image. Check if the host has sufficient memory.
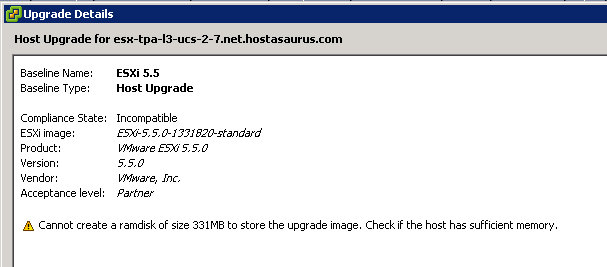
So that’s an odd one. The host in question has 256 GB of memory and 60 GB of local storage via a mirrored pair of hard drives on a raid controller. Only article on VMware’s website I could find even referencing that error was:
Host Upgrade Scan Messages in Update Manager
Which just gives a similar generic explanation:
The ESXi host disk must have enough free space to store the contents of the installer DVD.
The corresponding error code is SPACE_AVAIL_ISO.
These hosts were even fresh installs of 5.1 because their prior version was not upgraded, it was wiped and overwritten, so there should have not been any weird remnants causing something weird to have consumed space on the hard drive. I keep digging and find this article:
Creating a persistent scratch location for ESXi 4.x and 5.x (1033696)
Two things caught my attention:
VMware recommends that ESXi has a persistent scratch location available for storing temporary data including logs, diagnostic information, and system swap. (This is not a requirement, however.) Persistent scratch space may be provisioned on a FAT 16, VMFS, or NFS partition accessible by the ESXi host.
and
Scratch space is configured automatically during installation or first boot of an ESXi 4.1 U2 and later host, and does not usually need to be manually configured.
I came to the conclusion that perhaps my host’s scratch space was not set up correctly, allowing the ramdisk to fill with crap, resulting in there not being enough room to do the ESXi upgrade. So I wanted to find out where the scratch space was to see what was in it. Well when I did the storage view of the host’s local VMDK from within the vSphere Client, it was empty. Of course all the guests are on the SAN so I wasn’t expecting to see them, but I was expecting to see at least something based on that article telling me the local storage should be set up for scratch space automatically during install. I went through the “Configuring a persistent scratch location using the vSphere Client” section of that article and found something interesting when I went to:
- vSphere Client
- Home
- Inventory
- Hosts and Clusters
- Configuration
- Advanced Settings (in the Software box) -> ScratchConfig
- Over on the right you should see both ConfiguredScratchLocation and CurrentScratchLocation
or from the incredibly stupid vSphere 5.5 web client:
- Home
- vCenter Home
- Hosts & Clusters
- Expand down to the host you want to check
- Manage tab in the middle panel
- Settings selector button
- Expand ‘System’ to view ‘Advanced System Settings’
- Highlight ScratchConfig.ConfiguredScr… (since the rest is cut off, but it actually says ScratchConfig.ConfiguredScratchLocation)
- Click the pencil icon back at the top to edit and copy out the value showing.
- Now go back and highlight/edit the item right below it, looks like ScratchConfig.CurrentScratch… and copy out that value.
In my case, my configured scratch location (and current scratch location) showed something like this (anonymized):
/vmfs/volumes/11111111-22222222-333-444444444444
Okay, so how do we find out if that is an actual valid location? In vSphere Client, it’s easy; since you’re already on the Configuration tab, click up to Storage in the “Hardware” box, click on the local data store in the Datastores window, and in the Datastore Details box you should see “Location” specified:
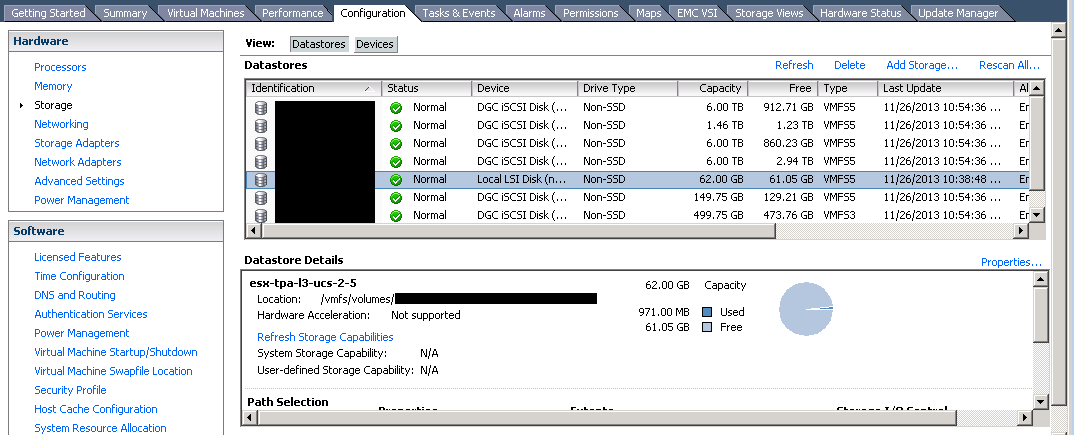
Sorry for the black cut-outs; those were the LUNs, but you see where location is in the lower part of the screen. Want to find the same information in the ‘new and improved’ web client? Too bad, it’s not there. The web client gives you the location in /vmfs/devices/disks/naa…. format and I don’t know if that’s valid for use in the scratch config or not:
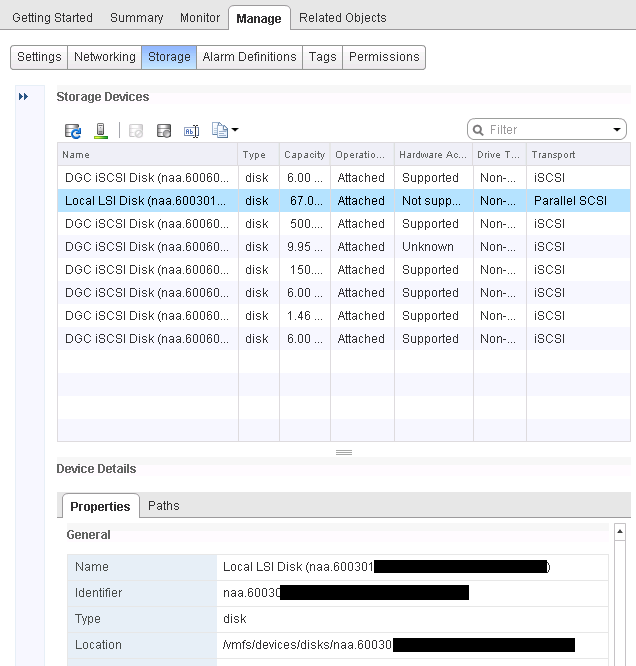
Oh, wait, I stand corrected, it appears you can get the location info in the /vmfs/volumes/ format if you go to the Storage area of the web client instead of the Hosts area, then find that local datastore and click the Summary tab:
- So, from Home, go to vCenter Home
- Storage
- Expand down as needed to see the relevant data center and data stores
- Click the one that matches the host in question
- Summary tab on the middle panel
Alright, so with all that out of the way, the important bit of information here is that what I had set for ScratchConfig.ConfiguredScratchLocation did NOT match a valid VMFS volume. Did not yet know why that was the case but decided to fix first and ask questions later. I opened the Datastore Browser on the local datastore on that host and created a folder called scratch. Next, went back to the advanced config ScratchConfig.ConfiguredScratchLocation setting and changed it to match the valid path to the new scratch folder; i.e. /vmfs/volumes/…uuid…/scratch
After a host reboot, my scratch folder now contains var, downloads, log, core and vsantraces; interesting. Went back to Update Manager and I was able to successfully upgrade the host to 5.5 now; it was no longer showing an error.
Okay, with all that behind me, I did finally figure out where the problem began. The server in question had a hardware failure after ESXi 5.1 had been installed. It uses a pair of mirrored drives on a raid controller solely for ESXi to boot from, and for scratch apparently. When the hardware failed, an identical new blade was installed in its place, the drives put back in, raid controller configured to import the foreign config found on the drives and we’re back in business. Apparently the UUID’s in the /vmfs/volumes/ paths are built based on some combination of data that includes the server hardware and/or raid controller, so the same drives in the new server had a different path, and the scratch directory had been wrong ever since that hardware swap.
So moral of that story is if you replace the hardware for a vSphere host, but keep the drives so an OS reinstall is not performed, your scratch path will probably be incorrect from that point forward.
Thanks for the article. Well written and came in handy for the Esxi 5.5 upgrade. I hate the webclient too, something nice to have but not for admin use.
I had to disable host lockdown mode :)